作者: ilezhizhe
书到了,争取看完吧~


C# 与 VB.NET 代码互转
http://converter.telerik.com/
源码来自SharpDevelop(对应软件自带解决方案转码工具)
http://www.icsharpcode.net/OpenSource/SD/Download/Default.aspx#SharpDevelop5x
DotnetBar 笔记
Advtree
parentFieldName=”ID,上级ID”
心累
浅谈文字编码和Unicode(上) [转]
出处:http://blog.csdn.net/fmddlmyy/archive/2007/02/14/1510189.aspx
我曾经写过一篇《谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词》(以下简称《谈谈Unicode编码》),在网上流传较广,我也收到不少朋友的反馈。本文探讨《谈谈Unicode编码》中未介绍或介绍较少的代码页、Surrogates等问题,补充一些Unicode资料,顺带介绍一下我最近编写的一个Unicode工具:UniToy。本文虽然是前文的补充,但在写作上尽量做到独立成篇。
标题中的“浅谈”是对自己的要求,我希望文字能尽量浅显易懂。但本文还是假设读者知道字节、16进制,了解《谈谈Unicode编码》中介绍过的字节序和Unicode的基本概念。
0 UniToy UniToy是我编写的一个小工具。通过UniToy,我们可以全方位、多角度地查看Unicode,了解Unicode和语言、代码页的关系,完成一些文字编码的相关工作。本文的一些内容是通过UniToy演示的。大家可以从我的网站(www.fmddlmyy.cn)下载UniToy的演示版本。 1 文字的显示1.1 发生了什么?
谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词 [转]
出处:http://www.fmddlmyy.cn/text6.html
这是一篇程序员写给程序员的趣味读物。所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级。整理这篇文章的动机是两个问题:
- 问题一:
- 使用Windows记事本的“另存为”,可以在GBK、Unicode、Unicode big endian和UTF-8这几种编码方式间相互转换。同样是txt文件,Windows是怎样识别编码方式的呢?
我很早前就发现Unicode、Unicode big endian和UTF-8编码的txt文件的开头会多出几个字节,分别是FF、FE(Unicode),FE、FF(Unicode big endian),EF、BB、BF(UTF-8)。但这些标记是基于什么标准呢?
- 问题二:
- 最近在网上看到一个ConvertUTF.c,实现了UTF-32、UTF-16和UTF-8这三种编码方式的相互转换。对于Unicode(UCS2)、GBK、UTF-8这些编码方式,我原来就了解。但这个程序让我有些糊涂,想不起来UTF-16和UCS2有什么关系。
查了查相关资料,总算将这些问题弄清楚了,顺带也了解了一些Unicode的细节。写成一篇文章,送给有过类似疑问的朋友。本文在写作时尽量做到通俗易懂,但要求读者知道什么是字节,什么是十六进制。
OllyICE 快捷键
无论当前的OllyDbg窗口是什么,这些快捷键均有效:
■ Ctrl+F2 – 重启程序,即重新启动被调试程序。如果当前没有调试的程序,OllyDbg会运行历史列表[history list]中的第一个程序。程序重启后,将会删除所有内存断点和硬件断点。
■ 译者注:从实际使用效果看,硬件断点在程序重启后并没有移除。
■ Alt+F2 – 关闭,即关闭被调试程序。如果程序仍在运行,会弹出一个提示信息,询问您是否要关闭程序。
■ F3 – 弹出“打开32位.EXE文件”对话框[Open 32-bit .EXE file],您可以选择可执行文件,并可以输入运行参数。
■ Alt+F5 – 让OllyDbg总在最前面。如果被调试程序在某个断点处发生中断,而这时调试程序弹出一个总在最前面的窗口(一般为模式消息或模式对话框[modal message or dialog]),它可能会遮住OllyDbg的一部分,但是我们又不能移动最小化这个窗口。激活OllyDbg(比如按任务栏上的标签)并按Alt+F5,OllyDbg将设置成总在最前面,会反过来遮住刚才那个窗口。如果您再按一下Alt+F5,OllyDbg会恢复到正常状态。OllyDbg是否处于总在最前面状态,将会保存,在下一次调试时依然有效。当前是否处于总在最前面状态,会显示在状态栏中。
过度汉化修正一例
前段时间帮朋友汉化了一个软件。昨天突然收到反馈说软件功能不正常——弹出的小窗口单位制显示错误。英文原版正常。除主程序外,替换了其他DLL文件,还是出错。那问题一定在主程序上了。
猜测可能是因为主界面的参数没正确传递给其他界面。试着还原
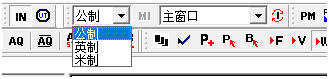
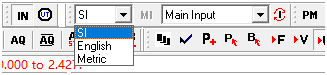
还原后,一切正常。
无奈,本人是完美主义者。其他都汉化了,怎么能少了这里呢?于是就继续”深入虎穴”。经过一番摸索后(技术不到家,不然应该很快就能找到方法,下次要好好看看PE结构,重定位这些知识了。),终于得”虎子”。特此记录下。(篇幅有限,步骤有删减,挑了主要部分,分析过程从略)
1、用Athena提取字符串,查找SI的调用地址
P.S.Unicode字符串SI比较短,需要在UltraEdit里找到字符,然后往Athena里添加记录。
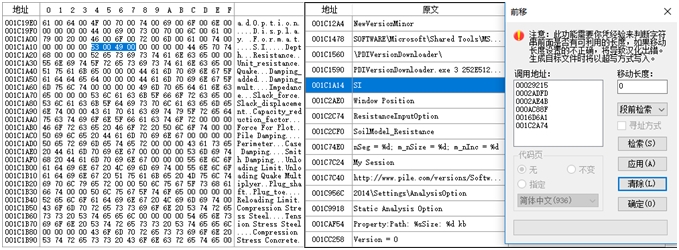
2、这个程序比较奇怪(也有可能当时汉化时,没过度汉化),主界面的三个选项(SI、ENGLISH、METRIC),后两个汉化了没事,主要因素在SI这个字符串上。所以就先来看看”米制”(Unicode码73 7C 36 52)
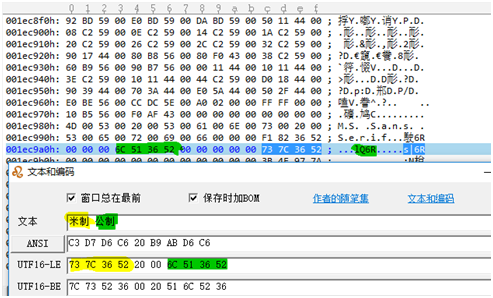
顺手在附近写下”公制”(Unicode码6C 51 36 52 )
那么,它们的相对地址是:
米制地址****AC(1EC9AC)
公制地址****A3
3、找到”米制”地址后,回到Athena看下调用地址0016D6C9
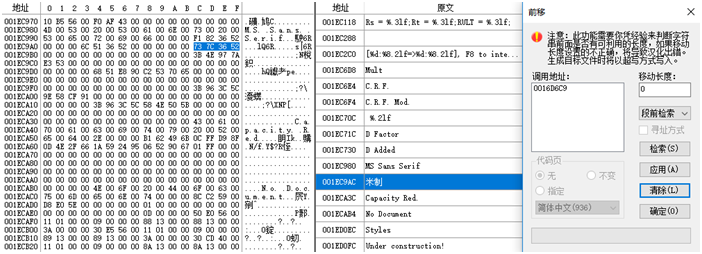
4、会想起步骤1中,SI的调用地址0016D6A1,和”米制”的调用地址接近。分别看下这两处调用地址。
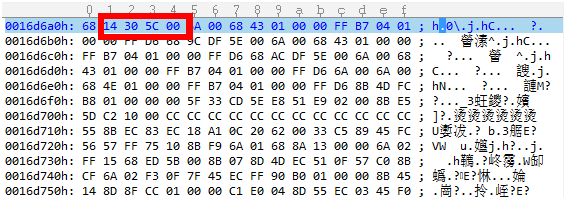
SI调用地址内容
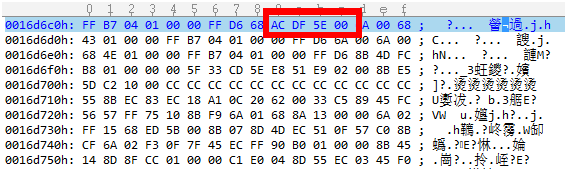
米制调用地址内容
5、回想起步骤2中,增加的”公制”字符串,将上图SI的调用地址改为(A3 DF 5E 00)

6、保存后,运行成功,无问题。
7、用OllyICE查看调用过程如下:
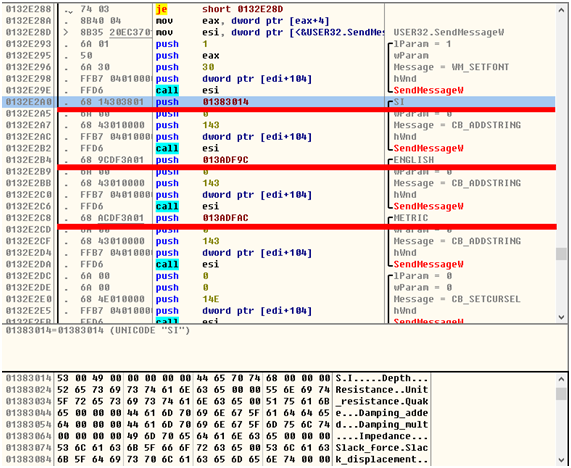
英文原版调用过程
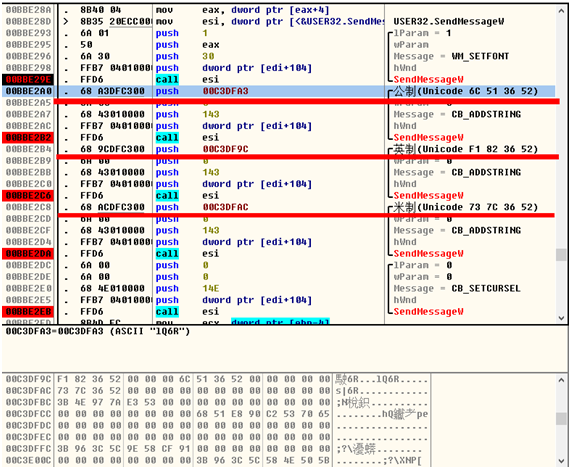
汉化修正版调用过程